利用できるPETs
秘密計算(MPC)
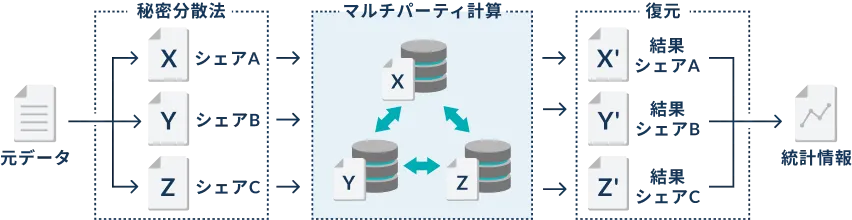
秘密計算手法のひとつであるMPC(Multi-Party Computation)を用いて、データを秘匿化したまま計算処理を実行することができます。データを複数のシェアに分け、それぞれを別々のサーバーに配置して、合計や平均などの統計情報を算出します。
複数のサーバーにデータが分散しているため、それぞれのサーバーに侵入されない限りデータを復元することはできません。
- 事業者間でデータを秘匿したまま、それぞれのデータを統合した計算処理を実行できる。
- 複数のサーバーにデータが分散しているため、それぞれのサーバーに侵入されない限りは、元の値を復元できない。
秘密計算(TEE)
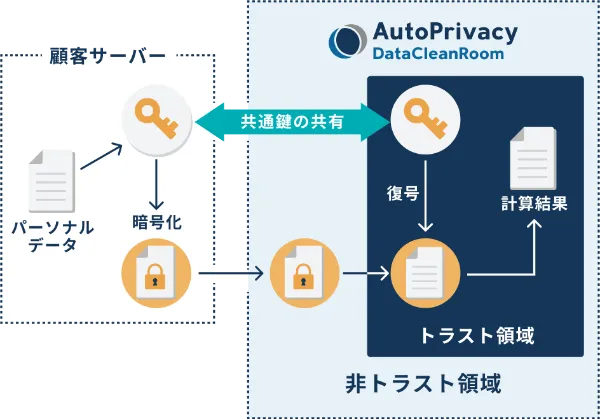
TEE(Trusted Execution Environment)を応用してデータクリーンルームを構築します。インテル® SGX用いてトラスト領域を構築し、その領域内でデータ処理を実行します。
トラスト領域内では、予め設定されたプログラムしか実行することができず、かつ実行されている処理を外部から見ることはできません。
データは暗号化した状態でトラスト領域に接続し、領域内で暗号を解くため、データの安全性を保ちつつも、平文のデータとほぼ同等の計算速度を実現することができます。
- 平文でのデータ処理とほぼ同等の計算速度を出せる。
ハードウェアベンダーの信頼性さえ担保しておけば、高い安全性を実現できる。
連合学習(Federated learning)
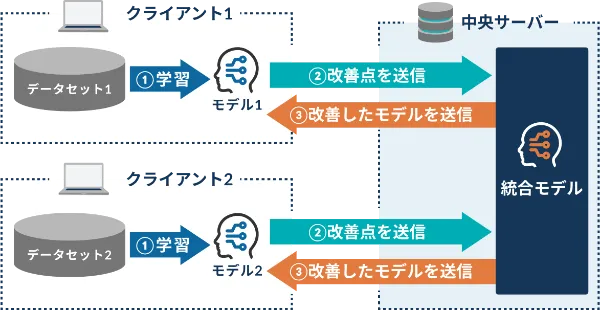
機械学習における学習法のひとつで、分散した学習用データを中央サーバーなどに集約することなく、モデルの学習と推論を行うことができます。
共通のモデルがインストールされた複数のクライアントで学習を行い、パラメータのみを中央サーバーに送信します。中央サーバーでは受け取ったパラメータをもとにモデルの改善を行い、それをまた各クライアントへ共有します。
- 学習用データを集約する必要がないので、高いプライバシー保護効果を期待できる。
- MPCでの機械学習と比較すると、学習時間がかなり短い。
k-匿名化
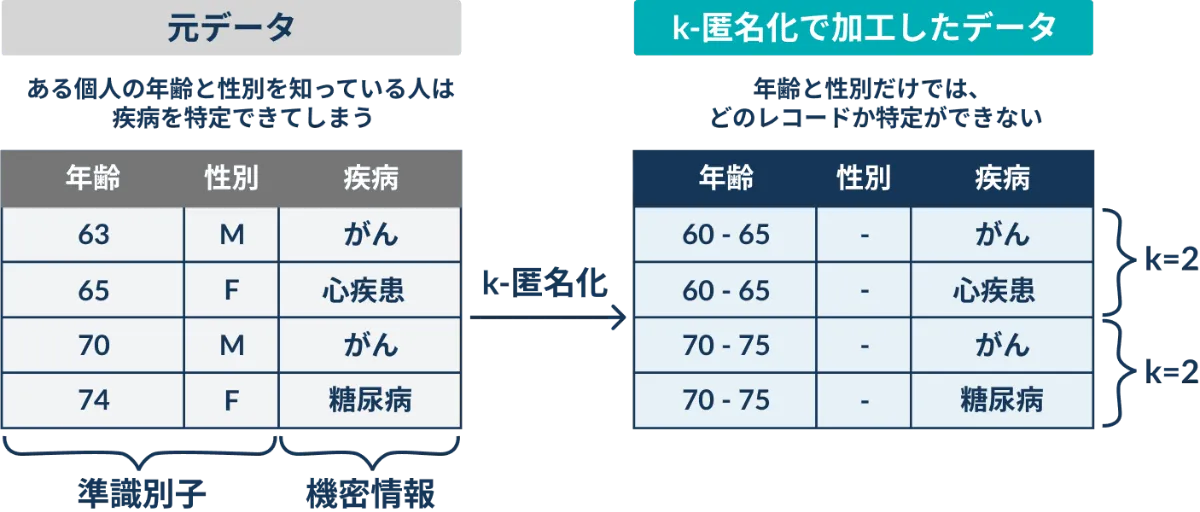
直接個人を特定できる情報が含まれていないデータでも、他の情報と組み合わせると個人を特定できる可能性があります。k-匿名化はデータに含まれる準識別子が、すべて等しいデータがk件以上になるようにデータを変換します。
k-匿名化を用いることで、個人特定可能性を低減させつつ、自由度の高いデータを分析に活用することができます。
- プライバシーを保護しつつ、情報の損失が少ないデータを得られる。
合成データ
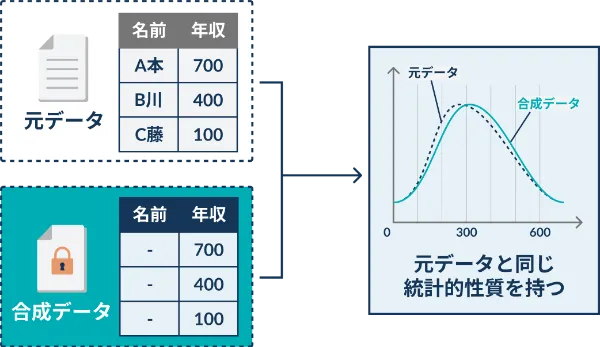
元データの統計的性質あるいは構造を維持しつつ、ある種のアルゴリズムや人工知能によって擬似データを作成します。疑似データから個人を特定することは非常に困難になります。
- プライバシーを高いレベルで保護しつつ、同じ特徴を持ったデータを生成することができる。
差分プライバシー
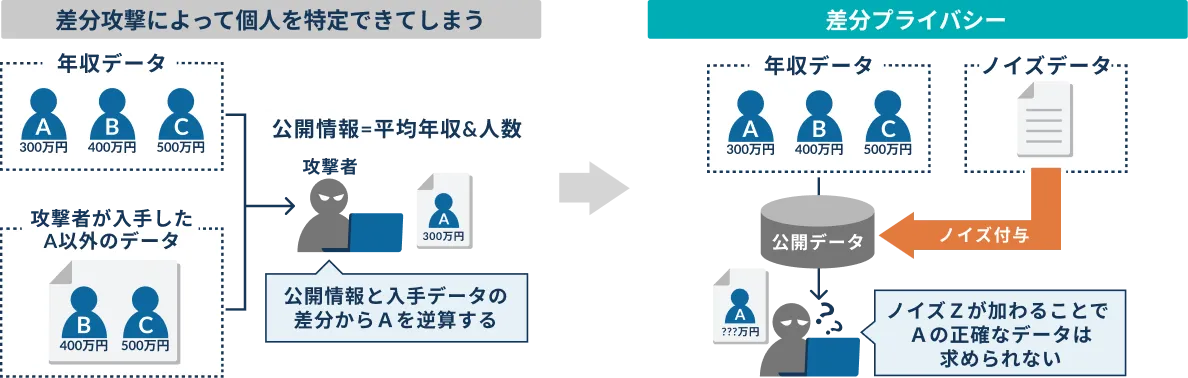
統計量に対して、分析に影響を及ぼさない程度のノイズデータを追加して、統計量から個人特定を防ぐための技術です。
例えば、ある3人の平均年収が公開されていたとして、その中の2人の年収データがあれば、残り1人の年収が特定できてしまいます。3人の平均年収にノイズを加えることによって、差分攻撃による個人特定の可能性を低減します。
- 差分攻撃によるプライバシーの侵害を防ぐことができる
データクリーンルームへの期待
AutoPrivacy DataCleanRoom独自の機能以外にも、一般的なPETsを用いてデータクリーンルームを構築することができます。
詳しく見る